Link to Video
https://www.youtube.com/watch?v=vjWRE0UnJDQ&list=PLSE8ODhjZXjbeqnfuvp30VrI7VXiFuOXS&index=17
History
MonetDB Design Goals
- analytics and scientific data mgmt
- autonomous index management
- knobs to tune
- cooperation with the OS
- based on binary relational model
MonetDB Architecture
DB Software Challenge
The only challenge is : how to I execute something declarative in the right sight? We have catalog manager, parser, RBO, CBO and execution engine such as Volcano model.
He doesn’t believe in RBO/CBO, and the volcano execution model. He wants something better.
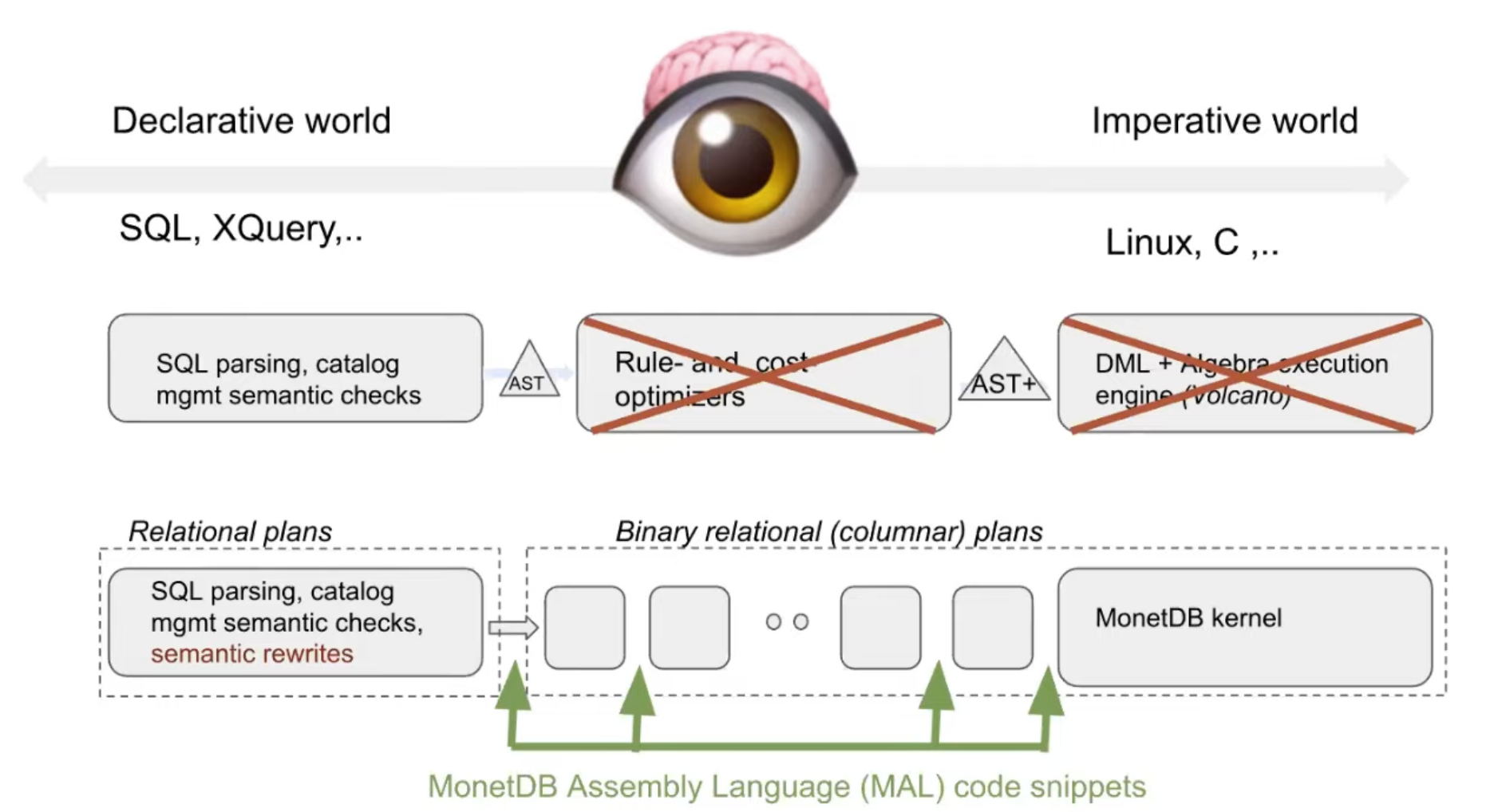
Parser still exists, but the plan + execution is run in MAL, and then run in MonetDB kernel.
MonetDB Kernel
is a VM specialized in DB operations. All instructions are strongly typed. Each kernel instruction includes property/cost based decisions.

Every decision is done on-the-fly, in operation level.
Optimizer Pipeline
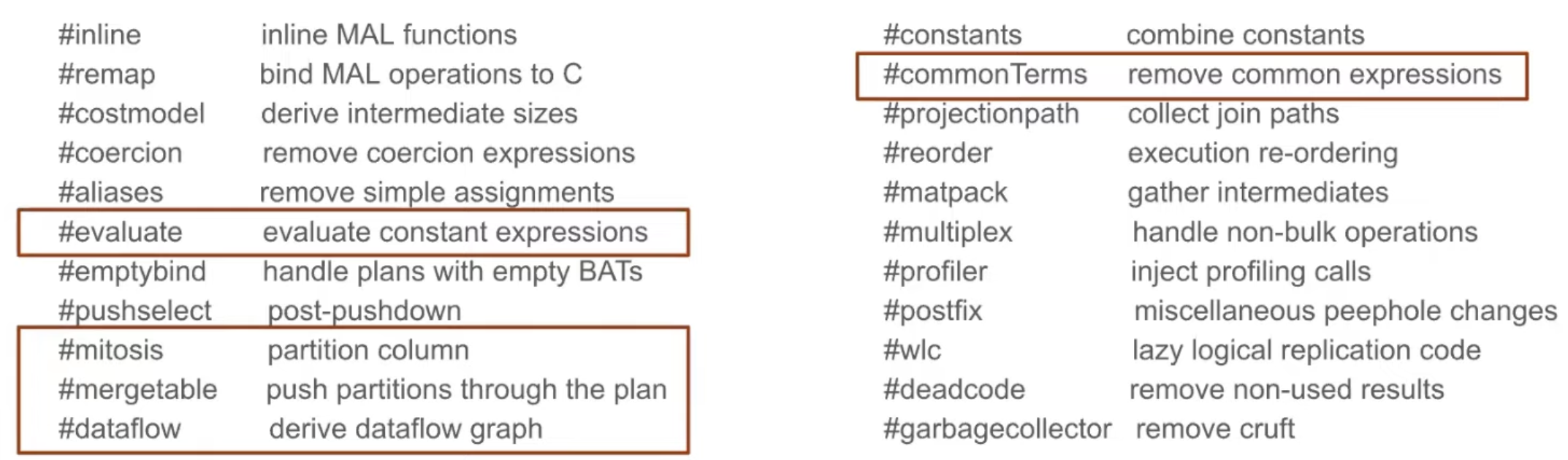
Optimizations include parallelization, constexpr eval, CSE, and et cetra.
Ex) TPC-H Q6


Step 3. perform optimization (e.g. DCE)
In fast running queries, the fastpath optimizer may matter more.
Columnar Storage
Storage Story - Column
MonetDB does not have a traditional buffer pool. To support Binary Association table, monetdb stores data in separate tables of (oid, value) by using mmaped files.
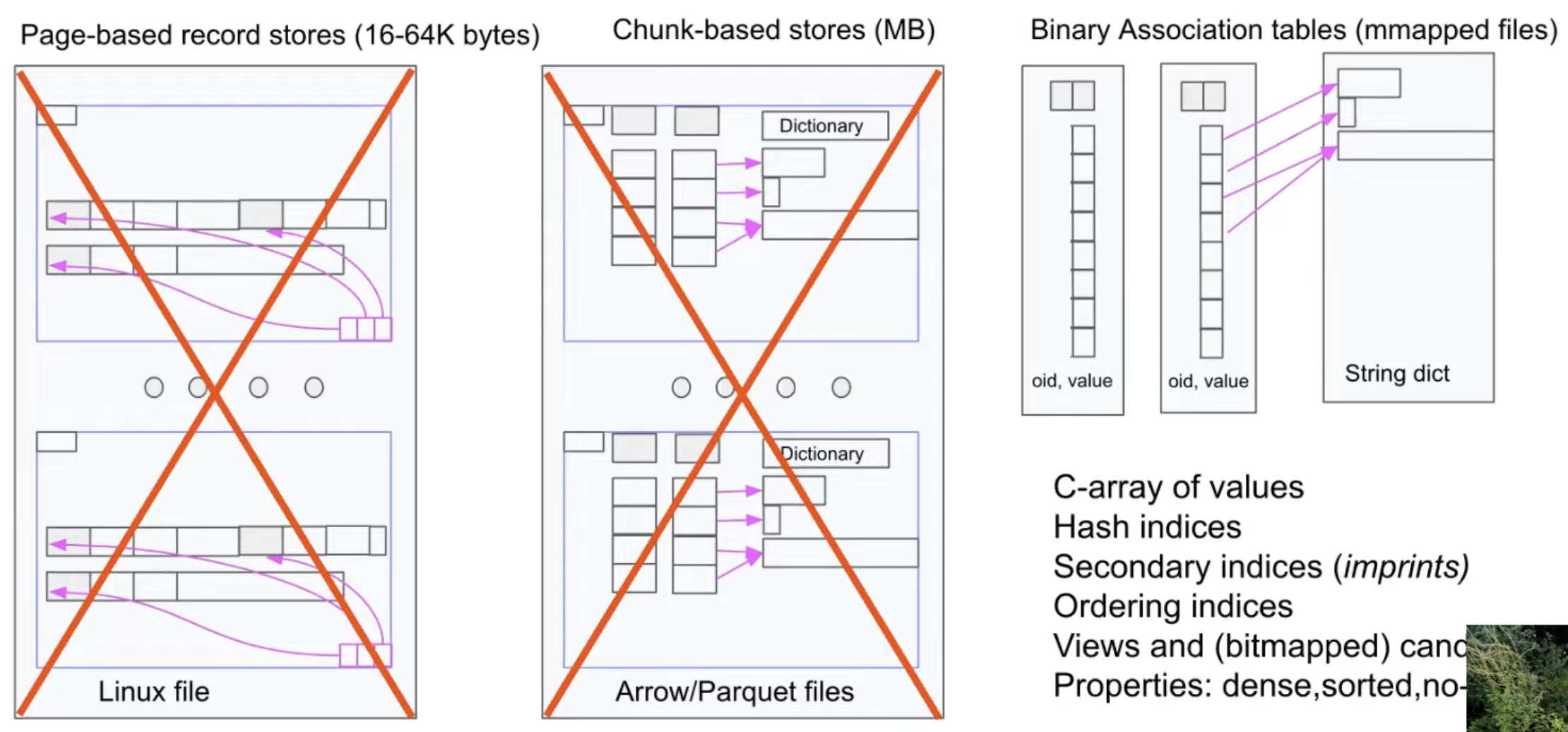
The data is simply stored as a a C-style array in the memory, managed by the OS. The indexes are build automatically. Get rid of your buffer manager! You don’t need it!
Details
Your RAM is the buffer space used by MonetDB. The system intellectually corporates with OS to perform buffer management, by referring RSS level of the OS. Transaction mgmt relies on fsync() of linux.
Execution Engine
Scale up before you scale out
Price model on AWS = nxGB + IOPS. So, we care reducing IOPS!
MonetDB kernel
MAL plan is a dataflow graph (DAG).
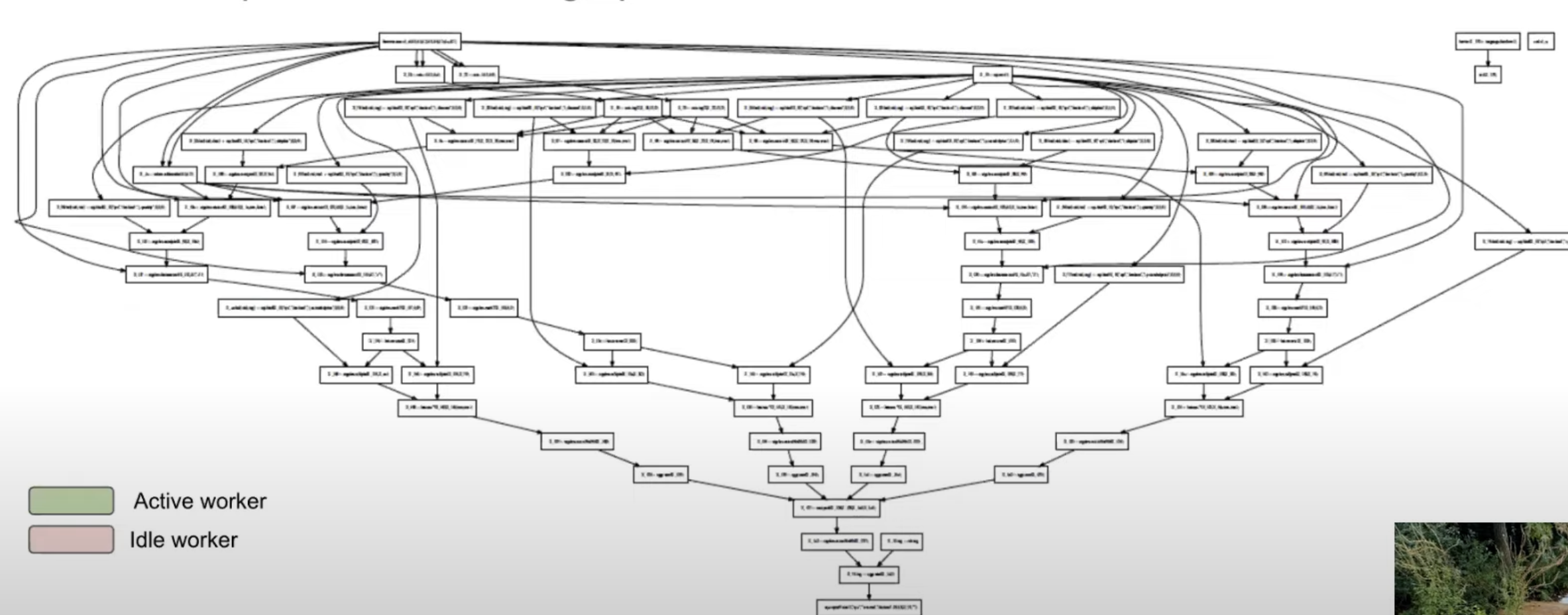
Apply pac-man style scheduling : introduce N workers to eat the graph.
Problem :
- intermediates are like hot potatoes : we want to get rid of them.
- All operations have different costs.
Go for speed
Since the table is seen as a array, the compiler may split the table with zero cost, and parallelize the query naturally.
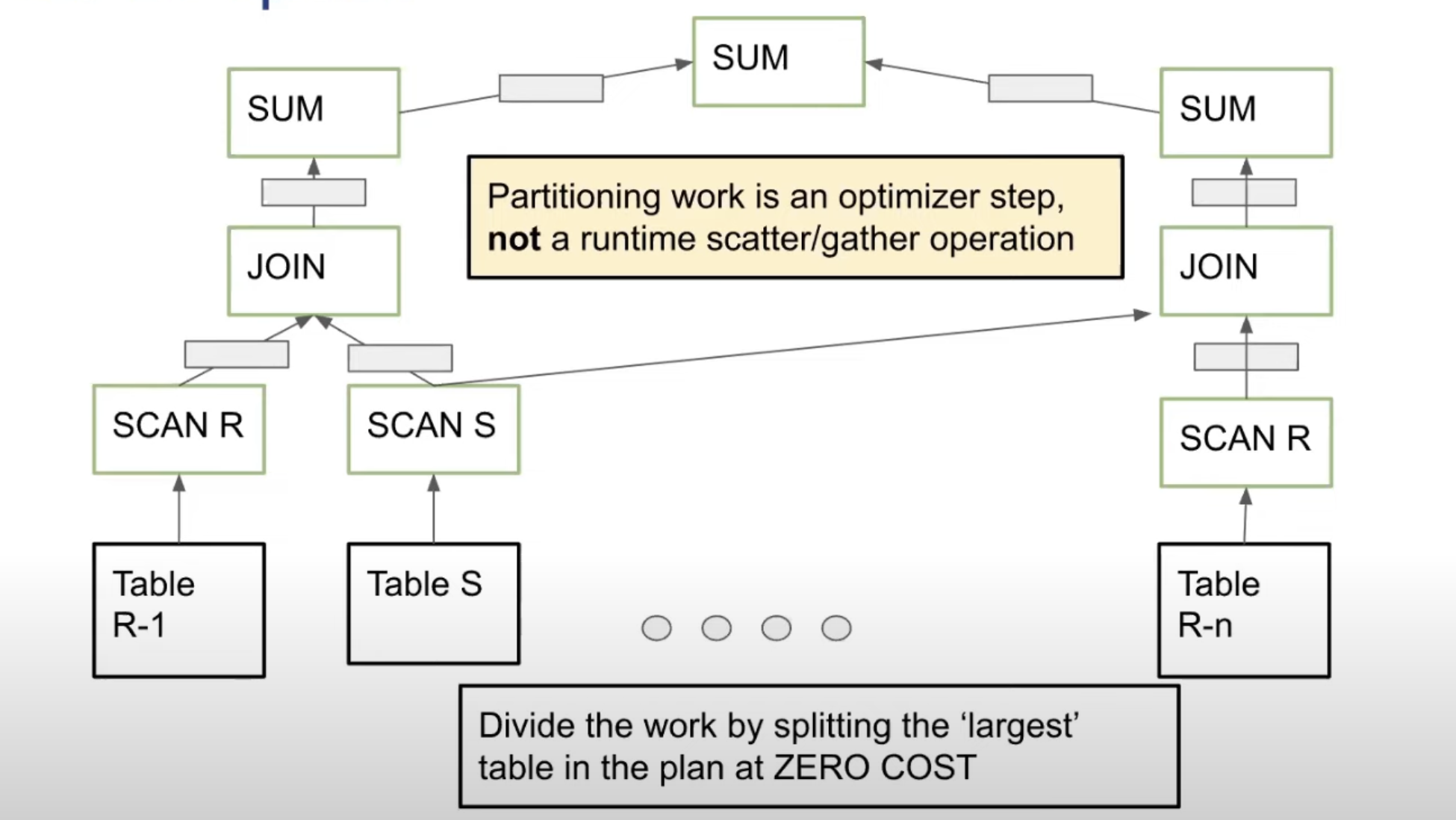
Adaptive vectorized processing
- Select largest table, and split it into chunks based on memory avail.
- Split column into vectors
- Propagate vectors through MAL plan
- Run program within the given memory bound
Experiment
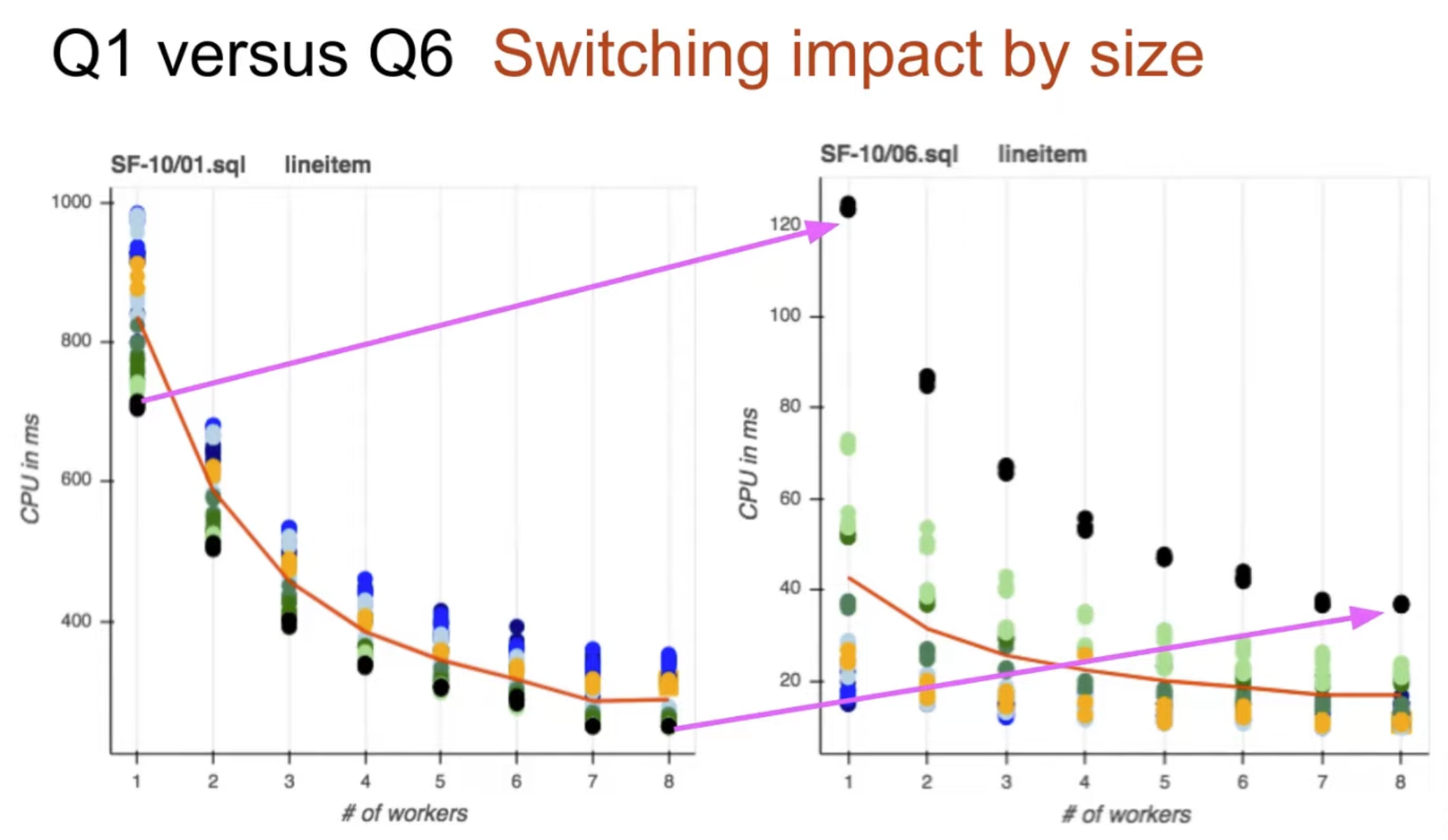
The optimal chunk size depends on : query / system load / HW
Lessons learned
DBMS products from research groups
A prototype DBMS is miles away from enterprice ready system.
- needs good coverage of SQL features
- need strong CI/CD environment
- needs many APIs
- needs UDFs to most languages
Benchmark Mirrors
Use microbenchmarks, workloads, … they are the first mirrors to steer to the direction of the desing/impl of a DBMS. They also convey a message by comparison.
TPC-H is not the real world

Questions
- Tried engine on serverless world? Nope not yet.
- Everything is a array, so have you tried on GPU?
- conclusion : barrier btw GPU/kernel is too big.
- needs tons of index probes to speed up
- Tried to use ring dataflow between GPUs-Cores, but not enough.
- Tried to use FPGA, but not a big improvement yet.
- Downsides of using mmap?
- There are some, but does not effects much in the view of whole system level
- Compression?
- we tried compression. every array(column) was compressed. but when running in memory, compression is not a good choice.
- CI/CD? How you did?
- Built tools since 2000s
- cmake -> boost -> builtbots for continuous integration
- when dealing with long-term project, you need to keep your rules.