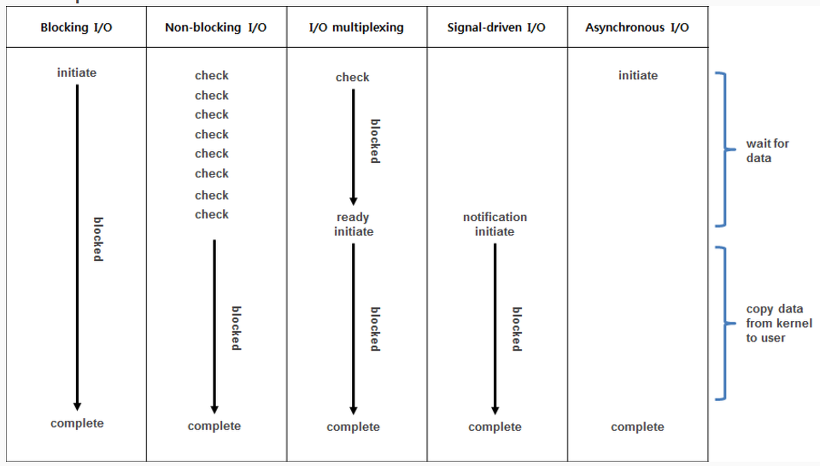
4 programming models for I/O
- Blocking vs Non-blocking : system call이 바로 return이 되느냐 안 되느냐?
- Synchronous vs Nonsynchronous : synch : 이벤트를 자신이 직접 처리 / async : callback 의해 처리
위 2x2 조합에 따라 네 가지 모델이 존재함.
-
sync block
- blocked by kernel until io is done
- e.g. traidional read() / write()
-
sync nonblock

- the call returns immediately not knowing the IO has finished
- user thread needs busy waiting to check if the IO has finished
- e.g. polling-based APIs
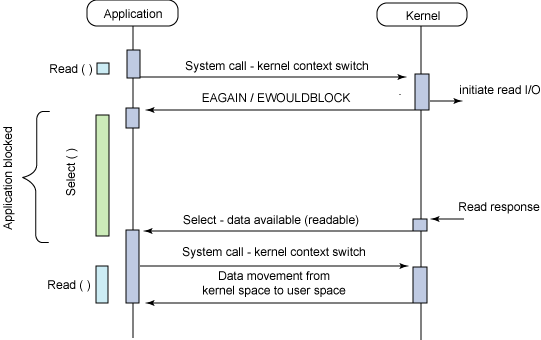
-
그림 기준으로, synch nonblock와 다른 것이, 둘다 바로 리턴하지만, 얘는 다른 function call로 blocking wait (이후 kernel이 blocking을 끊어주므로 asynchronous)하는 것이고, 저거는 read()로 계속 물어보는 것임.
-
주로, IO Multiplexing할 때 사용함.
- example : user calls another blocking function to wait for IO to be finished, this model is usually used when using IO multiplication
- select() : wait while any of the fd(s) until one fd becomes available
- 채팅서버와 같은 곳에 쓰임 (select 함수 자체는 synchronous함)
- 단 : 검사할 수 있는 fd 수가 1024로 제한
- epoll(): select()의 단점 극복 가능
- select() : wait while any of the fd(s) until one fd becomes available
- example : user calls another blocking function to wait for IO to be finished, this model is usually used when using IO multiplication
-
e.g. async-wait in JS, CompletableFuture in JAVA
-
async block
- 예시를 찾기 쉽지 않음.
- 어짜피 blocking일 거면 sync든 async든 무슨 상관일지?
-
async nonblock

- the kernel spawns callback function after IO is done
I/O-bound versus CPU-bound processes
(from IBM document)
A process that is I/O bound is one that performs more I/O than processing. A CPU-bound process does more processing than I/O. The Linux 2.6 scheduler actually favors I/O-bound processes because they commonly initiate an I/O and then block, which means other work can be efficiently interlaced between them.
Types of disk IO in linux
- Traditional read() / write()
- mmap
- Direct IO
- Async Direct IO
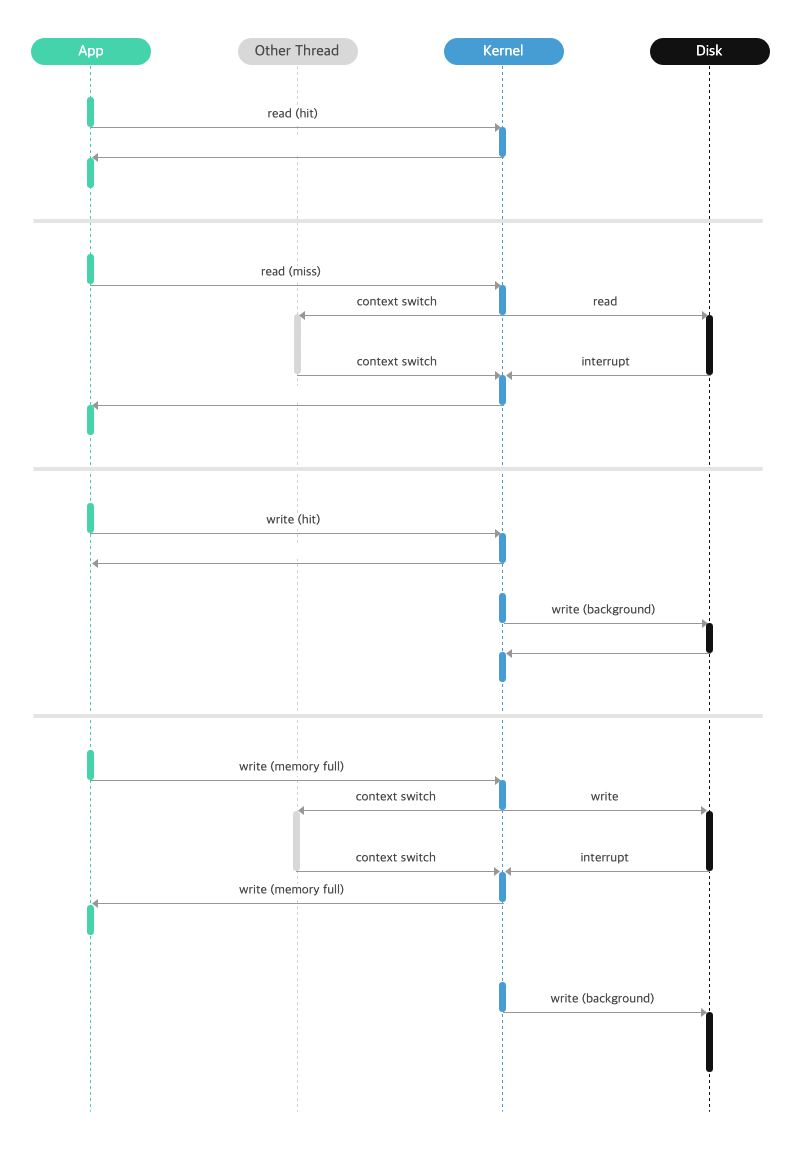
Traditional read() write()
- There exists a page cache of the kernel itself
- @read, If page cache hit, it will directly return from cache. Otherwise from disk to page cache, and then copy the data
- @write, write first to cache and some time afterward
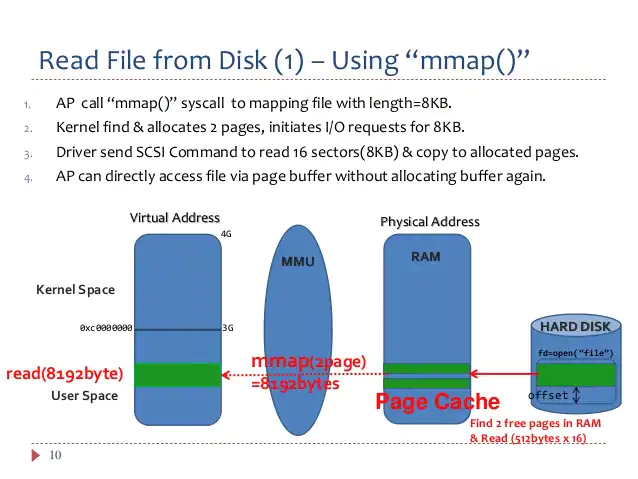
mmap()
- The kernel maps specific region of the file to process address space
- It also exploits page cache, so that the read/writes are done to the page cache
- fd = open(filename) → mmap(offset, fd)
- Multiple processes accessing the same region may share the mapped page cache
Direct IO (synch blocking)
Application schedules the IO itself. This involves opening the file with the O_DIRECT flag. Instead of accessing the cache, the disk is accessed directly which means that the calling thread will be put to sleep unconditionally. Furthermore, the disk controller will copy the data directly to userspace, bypassing the kernel.
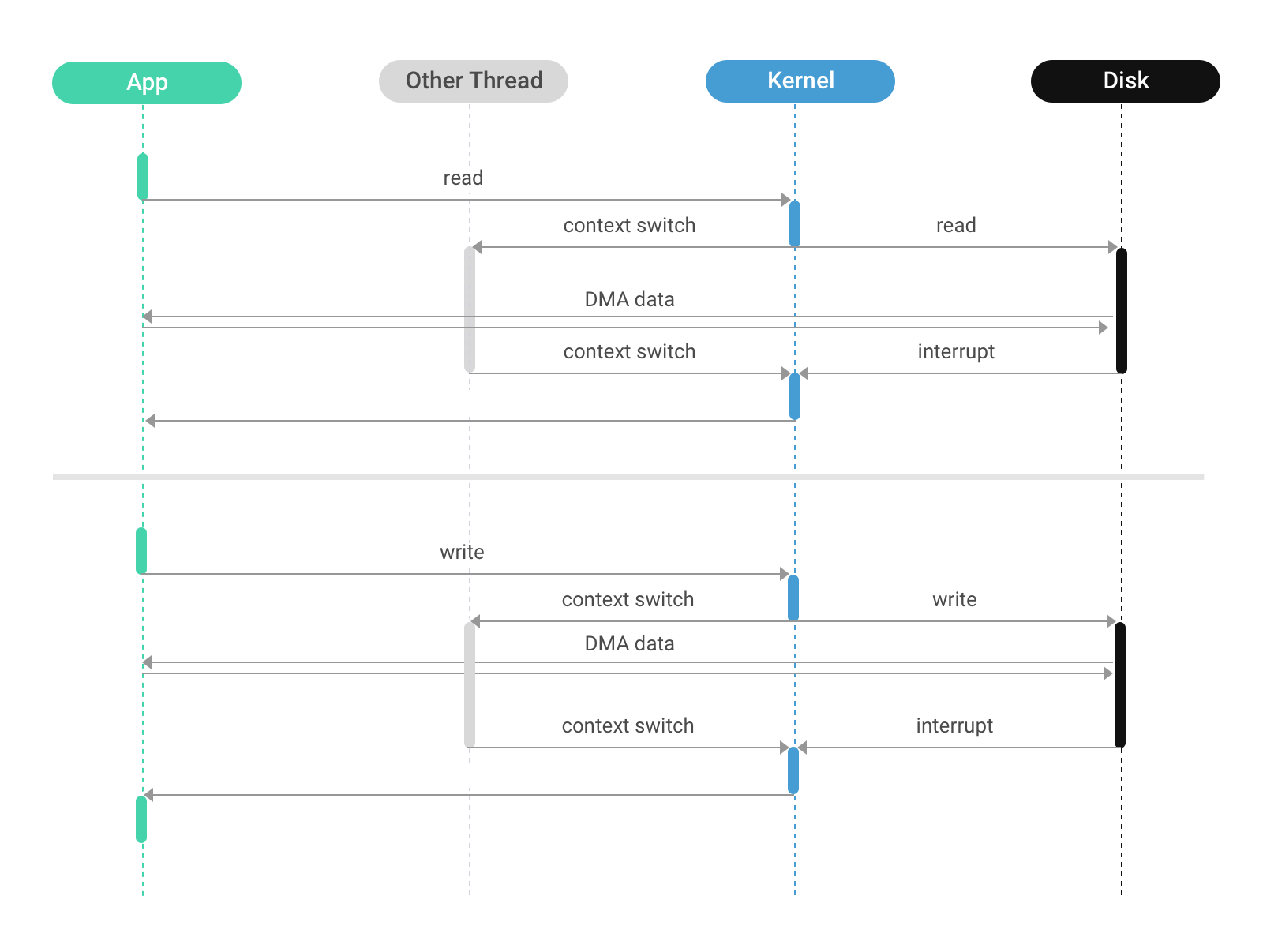
Async Direct IO (async nonblocking)
(https://developer.ibm.com/articles/l-async/#introduction-to-aio-for-linux)
A separate system call, io_getevents(2), is used to wait for and collect the results of completed I/O operations. Like DIO, the kernel’s page cache is bypassed.
The linux storage stack diagram
Ver. 2017
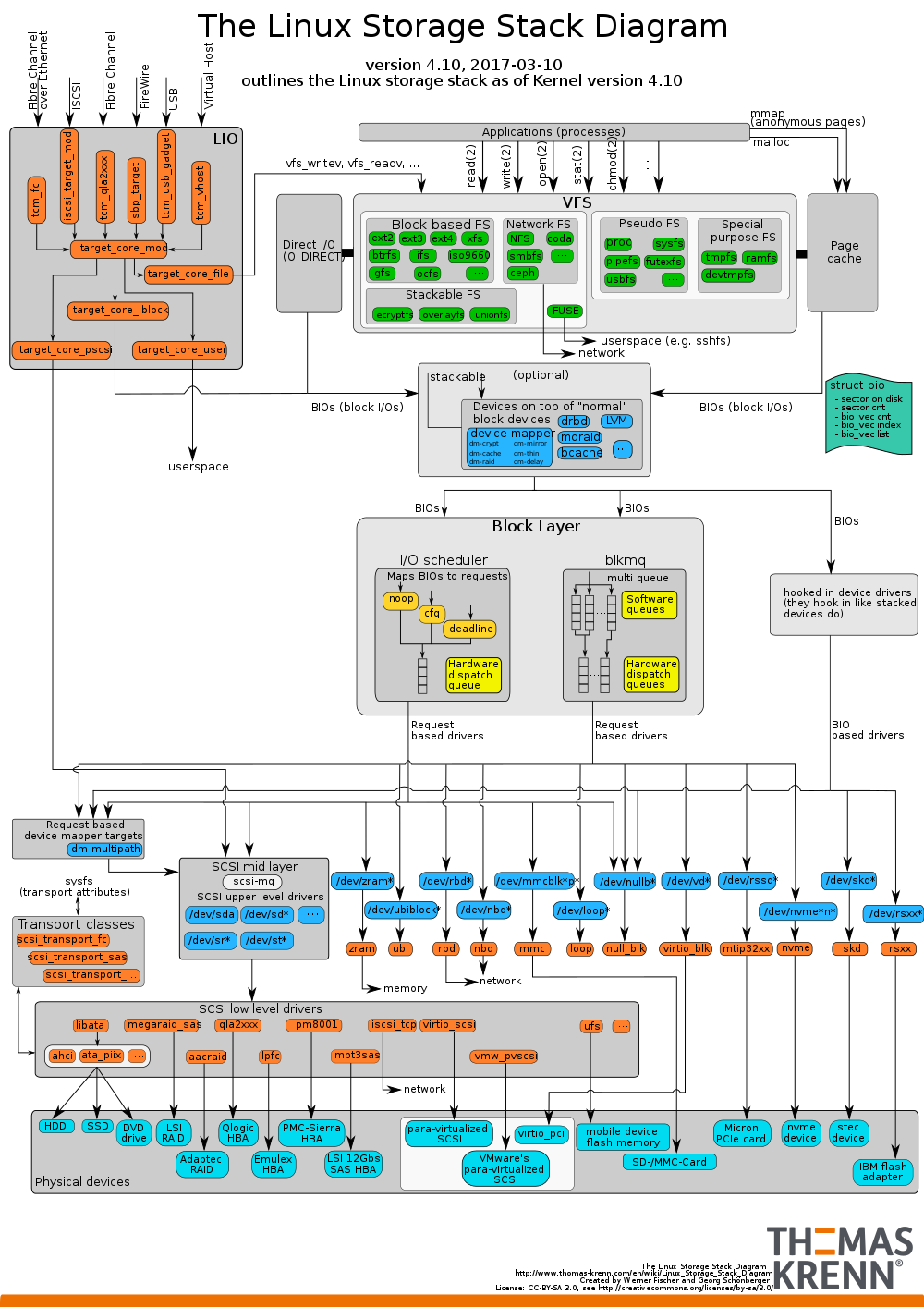
Supplementary